A Support Vector Machine (SVM) egy nagyon népszerű felügyelettel végrehajtott tanulási mód. Mai bejegyzésemben átnézzük működésének matematikai alapjait és egy naiv Python megvalósítását.
Az SVM alapvetően lineáris klasszifikációs1 problémák megoldására szolgál. Vagyis a kiindulási pontja, hogy van két lineárisan elválasztható csoportunk és szeretnénk meghatározni az ideális határt a kettő között. Valahogy így:

A fenti ábrán a két csoportot ugye könnyű elválasztani de vegyük észre, hogy végtelen számú lehetséges elválasztási lehetőség van. Fel is rajzoltam kettőt. A tesztadatok alapján mindkettő jó eredményt ad, de melyiket választanánk a gyakorlati életben? Én a B-t tenném. Azon egyszerű oknál, hogy az nagyjából egyforma távolságra helyezkedik el mindkét csoportól. Az SVM lényegében ezt a fajta gondolkozást próbálja megvalósítani. Vagyis azt a határvonalat keresi, ami egyforma távolságra van mindkét osztálytól. Ehhez pedig segéd “margókat” használ. Lényegében kijelöl két párhuzamos egyenest, nevezzük margóknak őket, a hipersík2 körül, és arra törekszik, hogy ezek a margók minél távolabb kerüljenek a hipersíktól. Valahogy így:

Vegyük észre, hogy mindkét margón van legalább egy megfigyelési pont. Ezek a “support vektorok”. Lényegében ezek azok a pontok amik számítanak a hipersík meghatározásában.
Szigorú margók
Ha a két osztályunk lineárisan jól elválasztható, akkor úgynevezett “szigorú margókat”3 tudunk alkalmazni. Mit is jelent ez? A hipersíkra a pontjai leírhatók a következő egyenlettel:
(1) 
Ahol:
— a pont koordinátája az i dimenzióban
— a hipersík definíciója az i dimenzióban
Ebből látni, hogy ha párhuzamost akarunk ezzel a hipersíkkal képezni az a követkő lesz:
(2) 
Ahol:
— egy 0-tól különböző konstans
Az SVM esetén ez a konstans 1 és -1 lesz, lévén a szignumfüggvény fogjuk az osztályok jelölésére használni. Vagyis az egyik osztály 1 lesz, a másik -1, és a pontok amik pontosan a határon vannak 0.
Lineárisan, sajnos, nem minden esetben egyértelműen választhatók el az osztályok. Ebben az esetben “lágy margót”4 használunk.
Lágy margó
Ezek az esetek így néznek ki:

Tehát van néhány pontunk, amik megakadályozzák, hogy egyértelműen elválaszthassuk a két osztályt lineárisan. Ilyenkor a Hinge loss-t hívjuk segítségül. Ennek a deffiniciója:
(3) 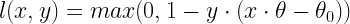
Amit újraírhatunk több mintavételre, így:
(4) 
Ahol:
— az valós osztálya (vagyis 1 vagy -1)
— az s-edik mintavétel valós osztálya (vagyis 1 vagy -1)
— a pont koordinátája
— az s-edik mintavétel pont koordinátája
— a Hinge loss értéke
Ez lényegében egy olyan függvény ami 0 értéket vesz fel, ha a pont a margó jó oldalán helyezkedik el, és egyenletesen növekszik ahogyan egyre távolodunk a rossz irányba. Nézzünk néhány példát:

A fenti pontok Hinge loss értéke valahogy így fog alakulni:
- — a margó jó oldalán helyezkedik el, tehát 0 lesz
- — pontos a margón van, ez is 0 lesz
- — a margó és a határvonal között található, tehát
képlettel kell számolni. Az értéke valahol 1 és 0 között lesz.
- — a határvonal rossz oldalán vagyunk, tehát ezt is
A Hinge loss segítségével most már tudjuk mérni a pontok rosszaságát, ellenben nem kezeli azt a problémát, hogy az SVM nullára állítaná a margók és a hipersík távolságát, mivel minimalizálni szeretné ezt a hibát. Ez úgy oldhatjuk meg, hogy bevezetünk egy új változót, ami leírja mekkora hibát vagyunk hajlandók elfogadni a margók növelése céljából. Jelöljük ezt az új értéket 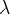
(5) ![J(\theta) = \left[\frac 1 n \sum_{i=1}^n \max\left(0, 1 - y_i(\theta \cdot x_i - \theta_0)\right) \right] + \lambda\lVert \theta \rVert^2](https://s0.wp.com/latex.php?latex=J%28%5Ctheta%29+%3D+%5Cleft%5B%5Cfrac+1+n+%5Csum_%7Bi%3D1%7D%5En+%5Cmax%5Cleft%280%2C+1+-+y_i%28%5Ctheta+%5Ccdot+x_i+-+%5Ctheta_0%29%5Cright%29+%5Cright%5D+%2B+%5Clambda%5ClVert+%5Ctheta+%5CrVert%5E2++++&bg=ffffff&fg=000000&s=2&c=20201002)
Ahol:
— a
vektor hossza. Vegyük észre, hogy a margók távolságot a hitpersíktól sehol nem tároltuk korábban. Mivel ugyanazt a síkot végtelen mennyiségű, eltérő hosszú vektorral le tudjuk írni, a
fogja tárolni számunkra. Mivel ezt szeretnénk maximalizálni, ami meg a
— a már említett kompromisszum mértéke a hibás kategorizálás és a széles margók között.
Naiv Python megvalósítás
Ha Pythonban dolgozunk akkor abban a szerencsés helyzetben vagyunk, hogy rengeteg gépi tanulással kapcsolatos könyvtár áll rendelkezésünkre. Az SVM-re is van már jó bevált könyvtár a scikit-learn-ben. Ennek ellenére nézzünk meg most egy naiv megvalósítást. Miért? A hozzám hasonló egyszerű lelkek számára akik jobban tudnak kódot olvasni mint matematikai leírást.
A célunk az, hogy egy “lágy margójú” SVM-t írjunk. Tehát az (5)-ben ismertetett 


(6) ![\theta = \theta - \eta \cdot \frac{d}{d\theta} \left[\frac 1 n \sum_{i=1}^n \max\left(0, 1 - y_i(\theta \cdot x_i - \theta_0)\right) + \frac{\lambda}{2}\lVert \theta \rVert^2 \right]](https://s0.wp.com/latex.php?latex=%5Ctheta+%3D+%5Ctheta+-+%5Ceta+%5Ccdot+%5Cfrac%7Bd%7D%7Bd%5Ctheta%7D+%5Cleft%5B%5Cfrac+1+n+%5Csum_%7Bi%3D1%7D%5En++%5Cmax%5Cleft%280%2C+1+-+y_i%28%5Ctheta+%5Ccdot+x_i+-+%5Ctheta_0%29%5Cright%29++%2B++%5Cfrac%7B%5Clambda%7D%7B2%7D%5ClVert+%5Ctheta+%5CrVert%5E2++++%5Cright%5D+++&bg=ffffff&fg=000000&s=2&c=20201002)
Ahol:
— a Stochastic gradient descent tanulási rátája. Ez az a változó, amit folyamatosan csökkentünk, ezzel megakadályozzuk a
— a kettővel való osztást azért használjuk, hogy a deriválás eredményét egyszerűsítsük.
A konkrétan megvalósítás pedig az úgynevezett Pegasos6 algoritmus lesz. Először is szimuláljunk egy adatsort:
import numpy as np # egy kis teszt adat 2D gaussian # pontok száma az egyes kategoriákban n = 50 cov = np.array([[1,0],[0,1]]) # 1-es csoport mean_1 = np.array([2,3]) # pontértékek x_1 = np.random.multivariate_normal(mean_1, cov, n) # címkék y_1 = np.ones(n) # -1-es csoport mean_2 = np.array([-1,-3]) x_2 = np.random.multivariate_normal(mean_2, cov, n) y_2 = np.ones(n)-2 # összekeverjük shuffled_idx = np.random.permutation(2*n) x = np.concatenate((x_1, x_2), axis=0) x = x[shuffled_idx] y = np.concatenate((y_1, y_2), axis=0) y = y[shuffled_idx]
Most írjuk meg a Pegasos algoritmust:
# frissités egyetlen megfigyelés alapjáán
def pegasos_single_step_update(
feature_vector,
label,
L,
eta,
current_theta,
current_theta_0):
# a Hinge loss
lh = label*(np.dot(current_theta,feature_vector)+current_theta_0)
# ha a Hinge loss nagyobb mint egy, vagyis a jó oldalon vagyunk es a margón kivul
eredmeny = [(1-L*eta)*current_theta, current_theta_0]
# ha a Hinge loss kisebb mint 1, vagyis a margó rossz oldalán vagyunk
if lh <= 1:
# theta frissitese
uj_theta = (1-L*eta)*(current_theta)+eta*np.dot(label, feature_vector)
uj_theta_0 = current_theta_0+(eta*float(label))
eredmeny = [uj_theta,uj_theta_0]
return tuple(eredmeny)
# T számú iterációt végzünk
# L -- a lambda
def pegasos(feature_matrix, labels, T, L):
theta = np.zeros((feature_matrix.shape[1])).T
theta_0 = 0
n = 1
for t in range(T):
for i in range(len(labels)):
# az eta-t folyamatosan csökkentjük az SGD-nek megfelelően
eta = 1/np.sqrt(n)
# frissités az egyedi megfigyelés alapján
theta, theta_0 = pegasos_single_step_update(feature_matrix[i], labels[i], float(L), eta, theta, theta_0)
n += 1
return (theta, theta_0)
Nézzük meg ezt a kódot egy kicsit részletesebben. Először is két függvényből áll. Az pegasos_single_step_update-ban lényegében a SVM, a pegasos ezzel szemben a stochastic gradient descent-et valósítja meg. A 11. sor a 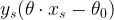
A pegasos függvényben az egyetlen érdekes rész a 33. sor, ahol látható, hogyan csökkentjük a tanulási rátát (
Végül alkalmazzuk az algoritmust a szimulált adatokon:
import matplotlib.pyplot as plt theta, theta_0 = pegasos(x,y,100, 1) # Ábrázoljuk x_1_plot = np.ravel(x_1.T).reshape(2,n) x_2_plot = np.ravel(x_2.T).reshape(2,n) plt.clf() plt.scatter(x_1_plot[0], x_1_plot[1], color="green") plt.scatter(x_2_plot[0], x_2_plot[1], color="navy") # plot the decision boundary xs = np.linspace(-3, 5) ys = -(theta[0]*xs + theta_0) / (theta[1] + 1e-16) plt.plot(xs, ys, 'k-', label="SVM eredmény", color="red") # margók tavolsag = 1/np.sqrt(np.sum(np.power(theta, 0.000000001))) ys_possitiv = -(theta[0]*xs + theta_0 - tavolsag*np.sqrt(1+np.power(theta[0], 2) ) ) / (theta[1] + 1e-16) ys_negativ = -(theta[0]*xs + theta_0 + tavolsag*np.sqrt(1+np.power(theta[0], 2) ) ) / (theta[1] + 1e-16) plt.plot(xs, ys_possitiv, '.', color="black") plt.plot(xs, ys_negativ, '.', label="margó", color="black") plt.legend() plt.show()

Ennyi is lenne. Az eredmény pedig nagyjából megfelel az elvárásunknak.
Lábjegyzet
- Persze léteznek újabb változatai, amik nem lineáris esetekre, meg felügyelet nélküli tanulásra is igazak, de most ezeket nem fogom tárgyalni.
- A megfigyelések tere lényegében egy hipertér, amit ugye egy hipersík választ két részre.
- Angolul: “hard margin”
- Angolul: “soft margin”
- Ez lényegében egy Ridge reguráció.
- Az eredeti leírása lsd. Shai Shalev-Shwartz és mások: Pegasos: Primal Estimated sub-GrAdient SOlver for SVM

Kedves Attila, kösz a cikket. Éppen az SVM-et tanulmányozom (értsd.: próbálom megérteni – :-)) . A cikk eleje egészen érthető, azt felfogtam, viszont bevallom férfiasan a “Hinge loss” után elvesztettem a fonalat. Bocs, nem kritikának szántam, valószínűleg az én készülékemben van a hiba… 🙂
KedvelésKedvelés
Kerbes Gábor, Ha esetleg meg tudnád fogalmazni konkrétabban mit nem értesz akkor elmagyarázom.
KedvelésKedvelés