A lineáris regresszió a mindennapi elemzések egyik legegyszerűbb és leggyakrabban alkalmazott eljárása. Ennek egyik érdekes változata a mai poszt tárgya.
Frissítés 2024.01: A STAN és PySTAN kód frissítve lett az új verziók szintakszisának megfelelően. STAN version: 2.34, PySTAN version: 3.8.0
Munkahelyi problémaként merült fel néhány napja, amit az egyik mobil szolgáltató szeretett volna megtudni: melyek azok az LTE (4G) átjátszótornyok, amelyeknek Downlink (DL) Througput-ja lassan deklarálódik. Adtak néhány ezer idősort. Nézzünk egy példát, nevezzük cella A-nak:

A feladat csak annyi volt, hogy megtaláljuk azokat az átjátszó tornyokat, amelyeknek a DL Throughput-ja a megfigyelt 10 napban trendszerűen csökkent. Ez egy egyszerű lineáris regresszió probléma. De van két kivitelezési probléma: egyrészt a zaj nem feltétlenül normál eloszlású: ahogy azt a fenti ábra is rögzíti, időről-időre nagy szélsőségek is megfigyelhetők. Másrészt a rendelkezésünkre álló idősor viszonylag rövid.
Nézzük ezeket a problémákat külön-külön!
Probléma 1: nem normál eloszlású zaj
Ugye, az egyszerű lineáris regresszió során a következő formulát használjuk:
(1)

Ahol:
— az y tengelymetszés
— a meredekség
— a zaj
Az általánosan bevett gyakorlat ilyen esetben a zajról feltételezni, hogy olyan normál eloszlású, aminek az átlaga 0. Ilyenkor a zajnak csak egyetlen paramétere ismeretlen: a szórása. Vagyis a fenti képlet felírható így is:
(2) 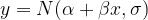
Ahol:
— a normál eloszlás jele
-
— a zaj szórása
A fenti esetben azonban élünk a gyanúval, hogy a zaj nem Gaussian. Ilyenkor valami robusztusabb megoldáshoz kell folyamodnunk. Az egyik javasolt megoldás lehet a Student t-eloszlás használata. Ugye, ha a szabadsági fok végtelen, akkor a Student t és a normál eloszlás megegyezik, viszont ahogy csökken a szabadsági fok, úgy növekszik a Student t farokterülete a normál eloszláshoz viszonyítva. Ez a tulajdonság értelemszerűen egy fajta robusztusságot biztosít számunkra a kiugró értékekkel szemben. Az általános t-eloszlásnak három paramétere van: az átlag, az arányositó1, és szabadsági fok. A szabadsági fok segítségével lényegében szabályozhatjuk a normál eloszlástól való eltérés mértékét. Tehát ekkor az (1) képlet a következő módon írható fel:
(3) 
Ahol:
— a Student t-eloszlás jele
— a szabadsági fok
Probléma 2: rövid idősor
Az, hogy lineáris trendet tudunk egy idősorra illeszteni, nem feltétlenül jelent trendszerűséget. Előfordulhat, hogy a zaj olyan szerencsétlen sorrendben szennyezi az adatsorunkat, hogy noha úgy tűnik, mintha lenne, de igazából nincs. Ugye, minél hosszabb a megfigyelésünk időtartama, annál kevésbé áll fent ennek a tévedésnek az esélye. Az ilyen problémák kiküszöbölésére szoktuk használni a Bayesian analízist. A lényegi különbség a frekvencialista megközelítéssel szemben, hogy itt nemcsak a legvalószínűbb lineáris kapcsolatot kapjuk meg eredményként, hanem az összes lehetséges megoldás-valószínűséget is.
Megvalósítás
Gondolom, a fentiek után nem meglepő a két probléma megoldásának ötvözete: így jutottam el a címben említett robusztus (probléma 1) Bayes (probléma 2) lineáris regresszióihoz.
A konkrét Python-megvalósítás, amit lentebb bemutatok, a STAN-on alapul. A STAN egy olyan C++-ban írt programozási nyelv, amit kifejezetten Bayes statisztikához dolgoztak ki. Két dolog miatt szeretjük: egyrészt gyors, másrészt több magasabb szintű nyelvhez is van interfésze. Vagyis egyaránt tudjuk használni R-ből, Python-ból, vagy MATLAB-ból. Ne is húzzuk tovább az időt, nézzük a STAN kódot2. Ezt a kódot a Python kód elején definiáljuk mint egy változót:
stan_code = """
data {
int<lower=1> N; // number of observations
int<lower=0> M; // number of values for credible interval estimation
int<lower=0> P; // number of values to predict
vector[N] x; // input data for the explanatory (independent) variable
vector[N] y; // input data for the response (dependent) variable
vector[M] x_cred; // x-values for credible interval estimation (should cover range of x)
vector[P] x_pred; // x-values for prediction
}
parameters {
real alpha; // intercept
real beta; // coefficient
real<lower=0> sigma; // scale of the t-distribution
real<lower=1> nu; // degrees of freedom of the t-distribution
}
transformed parameters {
vector[N] mu = alpha + beta * x; // mean response
vector[M] mu_cred = alpha + beta * x_cred; // mean response for credible int. estimation
vector[P] mu_pred = alpha + beta * x_pred; // mean response for prediction
}
model {
// Likelihood
// Student's t-distribution instead of normal for robustness
y ~ student_t(nu, mu, sigma);
// Uninformative priors on all parameters
alpha ~ normal(0, 1000);
beta ~ normal(0, 1000);
sigma ~ normal(0, 1000);
nu ~ gamma(2, 0.1);
}
generated quantities {
// Sample from the t-distribution at the values to predict (for prediction)
// real y_pred[P]; // korábbi STAN verziókban
array[P] real y_pred;
for (p in 1:P) {
y_pred[p] = student_t_rng(nu, mu_pred[p], sigma);
}
}
"""
Itt nem szeretnék nagyon belemenni a kód elemzésébe, szóval annak csak két részét nézzük meg: a data-t, és a modell-t. A data a bementi adatokat jelenti. Lényegében ezeket definiáljuk a lenti Python kódban. A második rész a megfigyelt 10 napban „meglepő módon” maga a Bayes modell. Az első sorában lényegében definiáljuk, hogy a (3)-nak megfelelően Student t-eloszlást fog követni a modell, míg lentebb beállítjuk a Bayes priorokat.
Most lássuk, hogy hívjuk meg ezt Pythonból:
# bemeneti adatok
print(celldata.head())
"""
cell datetime dl_throughput
0 A 2019-05-14 00:00:00 2.178312
1 A 2019-05-14 00:15:00 9.239398
2 A 2019-05-14 00:30:00 7.526668
3 A 2019-05-14 00:45:00 3.167329
4 A 2019-05-14 01:00:00 1.692141
"""
# dátum átalakitása egész számmá
import datetime
celldata["datetime"] = [ d.replace(tzinfo=datetime.timezone.utc).timestamp() for d in celldata["datetime" ] ]
# make smaller the datetime index for better calculation
celldata["datetime"] = [ (d-min(celldata["datetime" ]))/3600 for d in celldata["datetime" ] ]
# illesztjuk az adatokat
data = {'N': len(celldata["dl_throughput"]),
'M': 0,
'P': 0,
'y': celldata["dl_throughput"].values,
'x': celldata["datetime"].values,
'x_cred': [],
'x_pred': []
}
# PySTAN 2.x kód
# import pystan
# sm = pystan.StanModel(model_code=stan_code)
# fit = sm.sampling(data=dat, warmup=500, iter=1000, chains=4)
# PYSTAN 3.x kód
import stan
sm = stan.build(stan_code, data=data)
fit = sm.sample(num_chains=4, num_samples=1000)
# Bayesian eredmény ábrázolása -- a fit.plot csak PySTAN 2.8 érhető el
# fit.plot()
# plt.show()
Aminek az eredménye:

A fenti ábrából a bal oldali3 oszlop érdekesebb. Ez lényegében azt mutatja, hogy az egyes paraméter-értékeknek mekkora a valószínűsége. Amint az látható, a fenti cellában a béta -0,0002 és +0,00005 között helyezkedik el. Vagyis van arra esély, hogy egyáltalán nincs DL Throughput degradáció. Konkrétan:
# PySTAN 2.x-ben nem kell a flatten()
print("0-nál nagyobb béta valoszínüsége: ", 100*len([ x for x in fit['beta'].flatten() if x >= 0 ])/len(fit['beta'].flatten()) , '%')
# 0-nál nagyobb béta valoszínüsége: 4.2 %
És ez fontos.
Ez az a plusz információ, ami a Bayes-megközelítésből származik.
Most vegyünk néhány véletlenszerű mintát ebből a tartományból, és ábrázoljuk őket:
# Idősor ábrázolása
import random
import copy
n = 400
betas = copy.copy(fit['beta']).tolist()
alphas = copy.copy(fit['alpha']).tolist()
random_beta = random.sample(betas, n)
random_alpha = random.sample(alphas, n)
plt.plot(celldata["datetime"], celldata["dl_throughput"], color="C0", label="megfigyelés")
# véletlenszerű minta
for i in range(n):
xs = [ random_alpha[i]+(random_beta[i] * x) for x in celldata["datetime"] ]
plt.plot(celldata["datetime"], xs, color="red", alpha=0.01)
# a MAP becslés
# stan_mle = sm.optimizing(dat, init="0") # PyStan 2.x kód
stan_mle = {
'alpha': np.median(fit['alpha']),
'beta': np.median(fit['beta']),
'nu': np.median(fit['nu']),
'sigma': np.median(fit['sigma']),
} # ez nem túl szép de ez jutott gyorsan eszembe, ami mükődik PySTAN 3.x esetén
xs = [ stan_mle['alpha']+stan_mle['beta'] * x for x in celldata["datetime"] ]
plt.plot(celldata["datetime"], xs, color="yellow", label="legjobb lineáris regressziós model")
plt.title("DL Throughput a A mobil átjátszó tornyon")
plt.xlabel("időpont")
plt.ylabel("dl_throughput")
plt.legend()
plt.show()

Az eredmény megfelel az elvárásainknak, most már csak ellenőriznünk kell az eredményt.
Nézzük a zaj vajon normál eloszlású-e?
A vizuális megerősítés kedvért kezdjünk egy Q-Q ábrával.
celldata['trend'] = [ stan_mle['alpha'] + stan_mle['beta'] * x for x in range(len(celldata["dl_throughput"]))] celldata['residual'] = celldata["dl_throughput"]-celldata['trend'] stats.probplot(celldata['residual']/np.sqrt(np.var(celldata['residual'])), dist="norm", plot=plt) plt.show()

Ez nem igazán biztató. Ilyen ábra tipikusan olyan eloszlásokra jellemző, amelyeknek faroktartománya vastagabb, mint a normál eloszlásé. Nem mondjuk, hogy szerencsére, de azért számítottunk erre. Ha számszerűsíteni akarjuk a valószínűséget, hogy a zaj Gaussian eloszlásból származik, készíthetünk egy Kolmogorov–Smirnov, vagy egy Kolmogorov-Lilliefors tesztet.
import scipy.stats as stats stat, pvalue = stats.kstest(celldata['residual']/np.sqrt(np.var(celldata['residual'])),'norm')
Ami nekem a p értékre 1.130156154616202e-05-et eredményezett. Vagyis nyugodtan elutasíthatjuk a feltételezést, hogy a zaj normál eloszlásból származik.
Nézzük, hogy a Bayes modell által becsült Student t-eloszlás jobb-e.
sigma = stan_mle['sigma']
nu =stan_mle['nu']
binamount = 250
step = (max(celldata['residual'])-min(celldata['residual']))/binamount
bins = [ min(celldata['residual'])+s*step for s in range(binamount+2) ]
from math import gamma
def generalizedStudendT_Pdf(x, nu,mu,sigma):
return (gamma((nu+1)/2)/(gamma(nu/2)*np.sqrt(np.pi*nu)*sigma))*( 1+(1/nu)*((x-mu)/sigma)**2)**(-((nu+1)/2))
zaj_pdf = generalizedStudendT_Pdf(np.array(bins), nu, 0, sigma)
def generalizedStudendT_Sample(n, nu,mu,sigma):
from scipy.stats import t
r = t.rvs(nu, size=n)
return mu+sigma*r
zaj_sample = generalizedStudendT_Sample(len(celldata['residual']), nu, 0, sigma)
# Ábra
plt.clf()
# data
plt.hist(celldata['residual'], alpha=0.5, label="megfigyelés", density=True)
#plt.hist(zaj_sample, bins=bins, alpha=0.5, label="zajmodel", density=True)
# student T
plt.title("Megfigyelés vs Student t vs Normál eloszlás")
plt.plot(bins, zaj_pdf, alpha=0.5, label="Student t")
# standard normál pdf sűrűségfüggvénye
normalpdf = stats.norm.pdf(bins, 0, np.sqrt(np.var(celldata['residual'])))
plt.plot(bins, normalpdf, label="Normal")
plt.xlabel("zaj")
plt.ylabel("valószínűség")
plt.legend()
plt.show()

Ránézésre a Student t egyértelműen jobban illeszkedik. Nézzük, hogyan változott meg a Q-Q ábra:
import matplotlib.lines as mlines
plt.clf()
plt.scatter(sorted(celldata['residual']), sorted(zaj_sample))
plt.title("Q-Q ábra")
plt.ylabel("Model")
plt.xlabel("Megfigyelés")
x = np.linspace(min(celldata['residual']),max(celldata['residual']))
plt.plot(x,x, color="red")
plt.show()

Ez is jobbnak látszik. És megnyugtató, hogy a Kolmogorov–Smirnov eredménye is jobb:
stat, pvalue = stats.kstest(celldata['residual'],'t', args = (nu, 0, sigma))
Konkrétan a p-érték: 0.7783742596474882 lett. Vagyis elégetetten nyugtázhatjuk, hogy a zajt sikerült modelleznünk a Student t-eloszlással.
Lábjegyzet
- Angolul: scaling. Kissé megtévesztő, hogy a normál eloszlás szórásához hasonlóan
a jele, de a kettő nem ugyanaz.
- A kód eredeti forrása lsd. itt.
- A jobb oldal annyiban érdekes, hogy amíg véletlenszerű zajnak néz ki, addig örülünk.
Irodalom
- Adrian Baez-Ortega: Robust Bayesian linear regression with Stan in R
- A. Solomon Kurz: Robust Linear Regression with Student’s t-Distribution
- Cliburn Chan, Janice McCarthy: Computational Statistics in Python

“A Robusztus Bayes lineáris regresszió” bejegyzéshez egy hozzászólás