Az előző részben bemutattam, a kontrollált vizsgálat alapjait, és eljutottunk annak felismeréséig, hogy az Átlagos Kezelési Hatás naiv alkalmazása teljesen rossz eredményt produkálhat bizonyos esetekben. Azután megnéztük Fisher módszerét a probléma megkerülésére. A mai bejegyzésben megnézzük, hogy mit tehetünk ha nem akarjuk megkerülni a problémát.
Jerzy Neymant nem a „sharp” Hulla érdekelte; Fisherrel ellentétben; hanem az „Átlagos Kezelési Hatás”. Viszont azt állítani, hogy a kezelésnek általában nincs hatása sokkal gyengébb állítás, mint azt állítani, hogy egy esetben sincs. Könnyen előfordulhat olyan eset, hogy egyes esetekben javít, másokban ront a kezelés az eredeti állapoton.
Ennek megfelelően Neyman Null hipotézis:
(1) 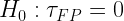
Ahol:
— az ATE, később kiderül miért használok másfajta jelölést itt
Az ATE számítása egyszerű. A bonyolultabb kérdés a konfidencia intervallum számítás. Magyarul menyire vagyunk biztosak a számított Átlagos Kezelési Hatás értékében? Értelemszerűen ehhez pedig annak a szórását kell kiszámolnunk.
Neyman esetében volt még egy fontos eltérés Fishertől. Őt nem az aktuális csoportra vonatkozó hatás érdekelte, hanem az “univerzális”. Vagyis az a kezelési hatás ami mindenkire, azokra is akik nem kerültek be a vizsgálatba, is vonatkozik. Ennek megfelelően a mintavételt is eltérően közelítette meg. Számára ez csak a “szuper-populáció” része. Ennek a szuper-populációnak a ATE-ját jelöljük 

Ha ebből a szempontból tekintünk az Átlagos Kezelési Hatásra, és emlékszünk a Centrális határeloszlás-tételre akkor, senki nem fog meglepődni ha azt mondom, aszimptotikusan a
(2) 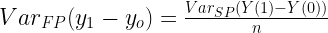
Ahol:
— az minta teszt értéke
-
— az minta kontroll értéke
— a szuper-populáció teszt értéke
— a szuper-populáció kontroll értéke
Amit átírhatunk így:
(3) 
Ebből az első két rész becslése elég egyszerű: behelyettesítjük a mintából számolt értékeket. A kérdés mi a harmadik rész? 0 a null hipotézis alapján.
A fentiek alapján, néhány átalakítás után Neyman eljutott addig, hogy a ATE varianciája a mintában:
(4) 
Ahol:
— az összes mintanagyság, vagyis teszt és kontroll csoport összesen
-
— a teszt csoport nagysága
Itt már csak az a probléma, hogy nem ismerjük a szuper-populáció szórásait. De Slotsky alapján ezt behelyettesítjük a mintából becsült értékekkel. Így a Null hipotézis alatt becsült varianciánk így alakul:
(5) 
Ezzel lényegében meg is oldottuk a Null hipotézis tesztelését. Tudjuk mi az elvárt értéke, az ATE, és tudjuk annak a varianciáját, amit az (5) add meg. Mikor fogjuk elutasítani a null hipotézist? Ha a 0 érték az 
Maradva az előző részben említett példánál számoljunk egy kicsit:
(6) 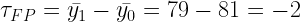
(7) 
(8) 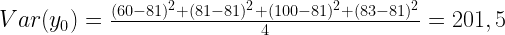
(9) 
Tehát a konfidencia intervallum, ha 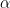
(10) 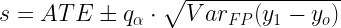
(11) ![s = -2\pm 1,96\cdot\sqrt{ 54,25 } \approx [-16,436 ; 12,436]](https://s0.wp.com/latex.php?latex=s+%3D+-2%5Cpm+1%2C96%5Ccdot%5Csqrt%7B++54%2C25++%7D++%5Capprox++%5B-16%2C436+%3B++12%2C436%5D+++&bg=ffffff&fg=000000&s=2&c=20201002)
Elutasíthatjuk ez alapján a Null hipotézist? Nem. Vagyis nincs elég bizonyítunk arra nézve, hogy az Átlagos Kezelési hatás nem 0. Ha akarjuk a p értéket is kiszámíthatjuk hozzá:
(12) 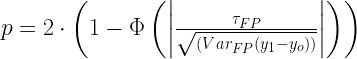
(13) 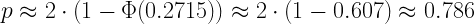
Ez elég távol van az áhított 0.05-től.
Irodalom
- Imbens és Rubin: Causal Inference for Statistics, Social, and Biomedical Sciences — Neyman’s Repeated Sampling Perspectivein Completely Randomized Experiments

“Neyman randomizált, kontrollált vizsgálatot — statisztikai alapok” bejegyzéshez egy hozzászólás