Ma egy olyan robusztus osztályozó eljárást ismertetek, amit hiányos adatsorokra is tudunk alkalmazni.
Az Elvárás-maximalizáló algoritmust 1977-ben publikálta Arthur Dempster, Nan Laird és Donald Rubin.1 A céljuk az volt, hogy kidolgozzanak egy olyan általános eljárást, amivel hiányos adatok esetén is lehetséges a maximum likelihood modellezés.
Kezdjük egy egyszerű osztályozási problémával: van sok megfigyelésünk, amik K független f(x) eloszlású populációból származnak. A példa kedvért legyen a K = 2, az f(x) legyen Gaussian, a megfigyelések pedig legyenek a következők:

A probléma az, hogy az osztályok cimkéje, sajnos nem áll rendelkezésünkre, mi pusztán látjuk:

A kérdés: mik a paraméterei a két populációknak? A normál eloszlásnak két paramétere van: az átlag (
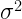

A fenti ábrán az átlagot keresztel jelöltem, míg a varianciát az átlag és a körülötte lévő szaggatott kör távolsága jelöli.
Hogy megoldjuk ezt a problémát, két részfeladatot kell elvégeznünk. Egyrészt ki kell számítanunk, hogy az egyes pontok milyen valószínűséggel tartoznak egy-egy osztályhoz. Ezt fogjuk megtenni az algoritmus Elvárás részében. Másrészt a végtelen számú lehetséges osztály közül ki kell választanunk azt a K számút, ami legjobban leírja az adatokat. Ezt fogjuk megtenni a Maximalizáció és az Optimalizáció során.
Az Elvárás
A célunk ebben a lépésben, hogy minden egyes pontot egy-egy osztályhoz rendeljünk. A példánkban azt feltételezzük, hogy minden egyes osztály egy-egy független Gaussian eloszlású forrásból származik. Ennek az eloszlásnak a Sűrűségfüggvénye több dimenzió esetén:
(1) 
Ezt nem is kell nagyon magyarázni, csak a 



Vagyis a fenti képlet megadja nekünk, hogy mekkora a valószínűsége egy megfigyelés adott modellből származásának. Ha több modellünk van, akkor segít a Bayes-tétel:
(2) 
Ahol:
— a modell jele
— a megfigyelés jele
— az i-edik konkrét megfigyelés
— annak valószínűsége, hogy i pont a j modellből származik, a Bayes posterior
— a j modell valószínűsége az összes esetek közül, a Bayes prior
— az összes modell valószínűségének összege
Azok számára, akik a kódot könnyeben olvassák, mint a matematikai kifejezéseket, nézzünk egy naiv Python megvalósítást.
Elvárás számítási példa
Először is készítsünk néhány teszt adatot: 50-50 megfigyelést két Gaussian populációból. Az egyik átlaga legyen (2; 3), a másiké (-1; -3), a szórása pedig legyen 1 mindkettőnek:
import numpy as np # egy kis teszt adat 2D gaussian # pontok száma az egyes kategoriákban n = 50 cov = np.array([[1,0],[0,1]]) # 1-es csoport mean_1 = np.array([2,3]) # pontértékek x_1 = np.random.multivariate_normal(mean_1, cov, n) # -1-es csoport mean_2 = np.array([-1,-3]) x_2 = np.random.multivariate_normal(mean_2, cov, n) # összekeverjük shuffled_idx = np.random.permutation(2*n) x = np.concatenate((x_1, x_2), axis=0) X = x[shuffled_idx]
Itt egy kicsit előre ugrunk, de ahhoz, hogy pontokat modellekhez rendeljünk szükségünk van modellekre is. Azt, hogy ezeket a modelleket, hogyan határozzuk meg, később részletezem. Most csak válaszunk K számú véletlenszerű modellt. Mondjuk Modell_1 átlaga legyen (0;-0,5), Modell_2-é pedig (0; 0). Mindkettő varianciája legyen 1,5:
mu = np.array([[0, -0.5], [0, 0]]) var = np.array([0.5, 0.5]) p = np.array([0.5, 0.5])
Ezt így ábrázoljuk:

Most nézzük az Elvárás lépés naiv Python–megvalósítását:
def estep(X: np.ndarray, mu_j:np.ndarray, sigma2_j: np.array, p_j: np.array) -> [np.ndarray, float]:
"""E-lépés
Args:
X: (n, d) -- az adatok
mu_j -- a felételezett Gaussian eloszlások átlaga
sigma2_j -- a felételezett Gaussian eloszlások varianciája
p -- az adott Gaussian eloszlás előfordulásának valószínűsége
Returns:
np.ndarray: (n, K) -- a valószínűsége, hogy az adott megfigyelés a j-ik Gaussian eloszláshoz tartozik
float: -- az egész modelre számitott hiba
"""
n, d = X.shape
post = []
costs = []
for i in range(n):
p_x_m = 1/np.power(2*np.pi*sigma2_j, d/2)* np.exp(-np.dot(np.power(X[i, :]-mu_j,2), np.ones(d))/(2*sigma2_j))
costs.append(np.log(sum(p_x_m*p_j)))
p_j_i = (p_x_m*p_j).T/np.sum(p_x_m*p_j)
post.append(p_j_i.tolist())
return np.array(post), np.sum(costs)
# E lépés
post, cost = estep(X, mu, var, p)
A fenti kód eléggé magától értetődő, nagy vonalakban: a 
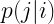
A kódban ugyanakkor van egy rész, a „costs”, amiről eddig nem volt szó. A Maximalizáció részben ezt is részletesebben tárgyaljuk.
A Maximalizáló
Eddig lényegében nem tettünk más, mint a pontokat modellekhez rendeltünk. Az Elvárás számítási példában említettem, ahhoz, hogy ezt megtegyük, rendelkeznünk kell már egy modellel. Csakhogy végtelen számú modell van. Hogyan válasszuk ki ezek közül a legjobbat? Ez lesz a Maximalizáció. Ha egy modell jól illeszkedik a pontokra, akkor
(4) 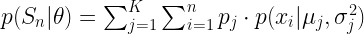
Ahol:
— a osztályok száma
— a megfigyelések száma
— a klasszifikációs modell
— a megfigyelések
— annak valószínűsége, hogy a megfigyelt adatok ebből az adott modellből származnak.
Tehát a fenti egyenlet megadja, mekkora a valószínűsége annak, hogy az adott megfigyelések a
Már csak az a kérdés, hogyan tudjuk ezt maximalizálni? Ebben segít a Maximum likelihood. Ez nem más, mint egy eljárás, ami megmutatja, hogy melyik paraméter illik a legjobban az adatokra. Korábban már részleteztem a számítását, ezért csak azt nézzük, hogy mi lesz az eredmény egy Gaussian modell esetén:
(5) 
(6) 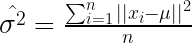
Mindkettő könnyen számítható: ugye, az (5)-ben minden ismert, a (6)-ban pedig 
Nézzük meg ezt akkor a teljes K darab Gaussian modell esetén. Itt lesz egy harmadik paraméter is a 


(7) 
Most nézzük a j Gaussian modellhez tartozó átlagot és varianciát. Ezek:
(8) 
(9) 
Lényegében nem csinálunk mást, csak súlyozunk egy Gaussian modell Maximum likelihood számítását azzal, hogy az adott megfigyelés a j modellhez tartozik.
Rendben. Mire jó ez? A (7), (8) és (9) a legjobb modell akkor, ha az Elvárás részben számolt valószínűségek igazak. Most nézzünk egy naiv megvalósítást.
Maximalizáló számítási példa
Folytatva a fenti példát:
def mstep(X: np.ndarray, post: np.ndarray) -> [np.ndarray,np.ndarray,np.ndarray]:
"""M-lépés
Args:
X: (n, d) -- az adatok
post: (n, K) -- a valoszinüsége, hogy az adott megfigyelés a j-ik Gaussian eloszláshoz tartozik
Returns:
mu (K,d) -- az új Gaussian modell átlagok
sigma2 (K) -- új Gaussian modell varianciak
p (K) -- az adott GAussian eloszlás elöfordulásának valoszinüsége
"""
n, d = X.shape
_, K = post.shape
mu = np.zeros((K, d))
sigma2 = np.zeros(K)
n_j = np.sum(post, axis=0)
p = n_j/n
for j in range(K):
mu[j, :] = post[:, j] @ X / n_j[j]
sigma2[j] = (((mu[j] - X)**2).sum(axis=1) @ post[:, j]) / (n_j[j]*d)
return mu, sigma2, p
mu, var, p = mstep(X, post)
Nézzük meg, hogyan változott a modell?

Az Optimalizáció
De van itt egy probléma. A fenti maximalizálás megadja a legjobb modellt az Elvárás részben számolt 
- Inicializáljunk a kezdeti modelleket.
- A pontokat ehhez a modellekhez rendeljük az Elvárás részben ismertetett módon.
- Az így meghatározott pontok segítségével frissítjük a modellt a Maximalizációnak megfelelően. Ha ez az új modell megegyezik a régi modellel, megállunk, ha nem akkor folytatjuk a második ponttól.
Elméletileg így már lehetséges a legjobb Maximum likelihood értékkel rendelkező modellt megtalálni. A gyakorlati élet sajnos nem ilyen egyszerű. Milyen hibát tudunk elkövetni? Egyrészt, ha a modellünk feltételezett eloszlása nem felel meg a valós eloszlástípusnak, akkor rossz lesz a Maximum likelihood számítás. A másik probléma, hogy — ugyanúgy mint a k-means osztályozás esetén — az algoritmus érzékeny a kezdeti inficiált modellek értékére. Az első problémát csak ésszel és odafigyeléssel lehet elkerülni. A második probléma elhárítására van gyakorlatunk. Először is futtassunk egy k-means osztályozást, hogy meghatározzuk az inficiáló modellek átlag értékét. Másrészt válasszunk akkora szórást ezeknek a modelleknek, amibe az összes megfigyelés belefér, mégpedig értelmezhető valószínűségi értéken belül.
Optimalizáció számítási példa
A naiv megvalósítást Pythonban:
def run(X: np.ndarray, mu: np.ndarray, var: np.ndarray, p: np.ndarray,
post: np.ndarray) -> [np.ndarray, np.ndarray, np.ndarray, np.ndarray, float]:
""" EM optimalizáció
Args:
X: (n, d) -- a megfigyelések
post: (n, K) -- a valoszinüsége, hogy az adott megfigyelés a j-ik Gaussian eloszláshoz tartozik
Returns:
GaussianMixture: the new gaussian mixture
np.ndarray: (n, K) array holding the soft counts
for all components for all examples
float: log-likelihood of the current assignment
"""
prev_cost = None
cost = None
while (prev_cost is None or (cost - prev_cost)/np.abs(cost) > 1e-6 ):
prev_cost = cost
post, cost = estep(X, mu, var, p)
mu, var, p = mstep(X, post)
return mu, var, p, post, cost
# modell inicializálása
mu = np.array([[0, -0.5],
[0, 0]])
var = np.array([1.5, 1.5])
p = np.array([0.5, 0.5])
K = mu.shape[0]
n = X.shape[0]
# modell optimalizálása
mu, var, p, post, cost = run(X, mu, var, np.ones(K) / K, np.ones((n, K)) / K)
A fenti kód magától érthető, de vegyük észre, hogy be van építve egy extra ellenőrzés: ha az új modell 

Számszerűsítve pedig:
- Modell_1
- átlag: (-0,89404661; -2.9812261)
- variancia: 1.14042149
- Modell_2:
- átlag: (1.80685051, 3.06734071)
- variancia: 0.76786612
Ez elég pontosnak látszik.
Hiányzó adatok
A fentieket olvasva talán felmerült az olvasóban: rendben, de mi ebben az érdekes? Ez csak egy egyszerű paraméterbecslés Maximum likelihooddal. Valóban. Viszont a fentieket tovább lehet fejleszteni olyan esetekre, amelyekben nem ismerjük a teljes adatsort. Mondjuk például, ha néhány koordináta hiányzik. Szimuláljuk ezt a fenti számítási példához hasonlóan. Amit úgy teszünk meg, hogy véletlenszerűen kicserélünk néhány koordinátát egy olyan értékre ami nem szerepel a megfigyelések között:
# néhány koordináta nodata értékével való helyettesítse
# mi az az érték amit a hiányzó elemek helyére írunk
nodata = -10
# helyettesítés
idxs = np.random.choice(range(len(X)), size=10)
for idx in idxs:
kordinata = np.random.choice(range(2))
if kordinata == 0:
X[idx] = (nodata,X[idx][1])
else:
X[idx] = (X[idx][0], nodata)
Ábrázolva:

A fenti ábrán vegyük észre a -10-es értékű hiányos koordinátájú megfigyeléseket. Az egyik lehetőség ilyen esetben az, hogy egyszerűen kihagyjuk ezeket a megfigyeléseket a további tesztből. Legyünk őszinték: ez egyszerű, de nem túl elegáns megoldás. Különösen akkor nem, ha a megfigyelések többségét ezek teszik ki.
Az EM algoritmus ezzel szemben lehetőséget kínál számunkra arra, hogy ezeket a hiányos adatokat is felhasználjuk. Hogyan? A peremeloszlások segítségével. A lényeg, hogy az (1)-est át lehet úgy alakítani, hogy a 
Hiányzó adatok számítási példa
Először nézzük, hogy hol kell módosítanunk a Elvárást. Két helyen: egyrészt maszkolnunk kell az adatokat, hogy ne vegyük figyelembe a hiányzó dimenziókat, másrészt a
def estep(X: np.ndarray, mu_j:np.ndarray, sigma2_j: np.array, p_j: np.array, nodata: float) -> [np.ndarray, float]:
n, d = X.shape
post = []
costs = []
U = np.ones((n,d))
U[X == nodata] = 0
for i in range(n):
p_x_m = 1/np.power(2*np.pi*sigma2_j, np.sum(U[i,:])/2)* np.exp(-np.dot(np.power(X[i, :]-mu_j,2), U[i,:])/(2*sigma2_j))
costs.append(np.log(sum(p_x_m*p_j)))
p_j_i = (p_x_m*p_j).T/np.sum(p_x_m*p_j)
post.append(p_j_i.tolist())
return np.array(post), np.sum(costs)
Most nézzük a Maximalizációs lépést! Itt lényegében ugyanezt a maszkolást kell megvalósítani. Ez eléggé magától értetődő. Kiegészítésnek csak annyi, hogy két extra ellenőrzést is megvalósítottam. Egyrészt bevezettem egy min_variance változót. Ez egy érték, aminél nem lehet egy osztály szórásnégyzete kisebb. Erre azért van szükség, mert ha magas a hiányos adatok aránya, akkor előfordulhat, hogy egyes osztályok lényegében eltűnnek. Másrészt a 20. sorban definiáltam, hogy minden egyes osztályhoz legalább egy teljes megfigyelésnek kell tartoznia.
def mstep(X: np.ndarray, post: np.ndarray, mu_j: np.ndarray, nodata: float,
min_variance: float = .25) -> [np.ndarray,np.ndarray,np.ndarray]:
n, d = X.shape
_, K = post.shape
mu = np.zeros((K, d))
sigma2 = np.zeros(K)
U = np.ones((n,d))
U[X == nodata] = 0
mask = (X == nodata)
n_j = np.sum(post, axis=0)
p = n_j/n
for j in range(K):
mu_tmp = (post[:, j] @ X) / (post[:, j] @ U)
for c in range(len(post[:,j] @ U)):
if (post[:,j]@U)[c] >= 1:
mu[j,c] = mu_tmp[c]
else:
mu[j,c] = mu_j[j,c]
sigma2_tmp = ( np.ma.array(np.power(mu[j] -X,2) , mask=mask ).sum(axis=1) @ post[:, j] )/ ( np.dot( post[:, j], np.sum(U, axis=1)) )
if sigma2_tmp >= min_variance:
sigma2[j] = sigma2_tmp
else:
sigma2[j] = min_variance
return (mu, sigma2, p)
Az optimalizáció majdnem ugyanaz, mint korábban, a hiányzó adatok és az extra ellenőrzések kezelésével kiegészítve:
def run(X: np.ndarray, mu: np.ndarray, var: np.ndarray, p: np.ndarray,
post: np.ndarray, nodata: float) -> [np.ndarray, np.ndarray, np.ndarray, np.ndarray, float]:
"""
Args:
X: (n, d) array holding the data
post: (n, K) array holding the soft counts
for all components for all examples
Returns:
GaussianMixture: the new gaussian mixture
np.ndarray: (n, K) array holding the soft counts
for all components for all examples
float: log-likelihood of the current assignment
"""
prev_cost = None
cost = None
while (prev_cost is None or (cost - prev_cost)/np.abs(cost) > 1e-6 ):
prev_cost = cost
post, cost = estep(X, mu, var, p, nodata)
mu, var, p = mstep(X, post, mu, nodata)
return mu, var, p, post, prev_cost
Most nézzük meg az eredményt a szimulált adatokra:
mu = np.array([[5, -2], [-5, 2]]) var = np.array([1.5, 1.5]) p = np.array([0.5, 0.5]) K = mu.shape[0] n = X.shape[0] mu, var, p, post, cost = run(X, mu, var, np.ones(K) / K, np.ones((n, K)) / K, nodata)
Ábrázolva:

Ezt az eredményt vártuk.
Végszó
Összességében az EM algoritmus egy elegáns megoldás arra, hogy minden információt felhasználjunk, ami a rendelkezésünkre áll. Nem csodaszer. Ha a megfigyelések többsége teljes, a hiányos adatok elhagyása bizonyos esetekben jobb eredményt tud produkálni. De ahogy növekszik a részlegesen nem ismert adatmenyiség, egyre inkább szükségünk van arra, hogy a megfigyelésekből minden információt kinyerjünk Ilyen esetekben az EM egyértelműen jobb megoldás mint az hiányos adatok kihagyása.
Lábjegyzet
- Az eredeti tanulmány: Maximum Likelihood from Incomplete Data via the EM Algorithm
- Itt egy kis zavar van az Erőben. Ugye egy folytonos változó esetén ez egyes pontok valószínűsége mindig 0, de most ugorjuk át ezt a problémát. Ha belemennénk sokkal hosszabbnak kellene lennie a levezetésnek.

“Elvárás-maximalizáló algoritmus” bejegyzéshez egy hozzászólás