A mai bejegyzésben egy igen népszerű témához kapcsolódunk: a Nagy Nyelvi Modellekhez (Large Language Models). Egy átlagos ember számára valószínűleg a ChatGPT 3.5 megjelenése volt 2022 legnagyobb mesterséges intelligenciával kapcsolatos híre. Ebben a bejegyzésben elemezzük, hogy miben lépet előre a 3.5 modell a ChatGPT 3-hoz képest.
ChatGPT
A ChatGPT megjelenésével egyértelműen a figyelem középpontjába kerültek a nyelvi modellek. Habár technológiai szempontból a ChatGPT nem jelent áttörést, népszerűségben határozottan igen. A modell alapvetően a 2017-ben debütáló Transformer-en nyugszik. A fejlesztése 2018-ban vette kezdetét, de csak 2022 végén vált elérhetővé a szélesebb közönség számára a 3.5-ös verzió bemutatásával. Ekkor azonban robbanásszerűen hatalmas népszerűségre tett szert. Egy hét alatt 1 millió felhasználó regisztrált (szemléltetésképpen: a Facebooknak ehhez 10 hónapra volt szüksége). 2023 áprilisában és májusában az oldalt összesen 1,8 milliárd látogatás érte el. Miért? Szerintem ennek két oka van. Egyrészt a modell rendkívül felhasználóbarát. Mindenkinek ismerős és egyszerűen kezelhető chatfelületet biztosít. Másrészt pedig ez a modell valóban működik. A ChatGPT lehetővé teszi a felhasználók számára, hogy szabadon kommunikáljanak a rendszerrel természetes nyelven, mintha egy valódi beszélgetést folytatnának egy másik emberrel. A modell gyors válaszidővel rendelkezik, és ezek a válaszok koherensek és természetesnek tünnek.
A szövegek koherenciájában történő fejlődés két dologra vezethető vissza, ezek közül az egyiket fogjuk mai bejegyzésünkben részletesebben körbejárni.
- A GPT 3.5 sokkal több, pontosan számolva 175 milliárd, paraméterrel rendelkezik a korábban elérhető modellekhez képest. A GPT-4-nek pedig még ennél is több, összesen 1 billió paramétere van. Ez alapvetően azt jelenti, hogy a modell összetettebb. Ez azt is jelenti, hogy nagyobb mennyiségű adaton kellett tanítani a korábbi változatokhoz képest. Természetesen nagyobb számítási kapacitásra is szükség volt. Röviden: sok pénz, sok adat és nagy számítási kapacitás találkozott. Nem fogunk mélyebben ezzel a ponttal foglalkozni, mivel nagyon kevés olvasó kerülhet abba a helyzetbe, hogy dollármilliókat költsön arra, hogy nulláról tanítson egy ilyen modellt.
- A másik pont azonban sokkal érdekesebb: a GPT 3.5-t rendkívül hatékonyan finomhangolták. Korábban több összetettebb mesterséges intelligencia modell elbukott a felhasználók körében ennek a hiánya miatt. Gondoljunk csak a Microsoft Tay-re, amit a rasszista szövegek generálása miatt kellett leállítani. Ennek a problémának a gyökere visszavezethető az első pontra: sok adat. Nagy modellekhez nagy adatmennyiség szükséges, azonban ez gyakran az általános szövegminőség romlását is eredményezi. A ChatGPT esetében viszont sikeresen orvosolták ezt a problémát a Megerősített Tanulás Emberi Visszajelzésből (angolul: Reinforcement Learning from Human Feedback) segítségével. Ezt fogjuk most kicsit részletesebben megvizsgálni.
Megerősített Tanulási modell tanítása
A klasszikus gépi tanulásnál általában olyan adatokra koncentrálunk, melyek nem változnak attól, hogy milyen jól teljesít az algoritmusunk. Például, ha meg akarjuk határozni, hogy mennyi homok van egy olajfúró kútban, az nem fog változni attól, hogy mennyire jó a modellünk. Azonban néha vannak olyan helyzetek, amikor ez nem így van. Például, ha egy játékban a modellünk egyik játékosként vesz részt. Ekkor az, hogy milyen lépéseket tett korábban (és természetesen az ellenfél lépései is), hatással van arra, hogy mi lenne a legjobb következő lépés. Az igazi cél, hogy megnyerjük a játékot, a saját korábbi lépéseink sorozatától függ. Ráadásul a játékokban általában többféle stratégia vezethet a győzelemhez. Az ilyen problémákra született a megerősítéses tanulás (angolul: Reinforcement Learning). Ilyenkor egy “gépi ügynök” fedezi fel a környezetét és jutalmakat vagy büntetéseket kap a cselekedetei alapján. Az a cél, hogy az algoritmus a jutalmakat maximalizálja.
Nem nehéz észrevenni, hogy a nyelvi modelleknek is gyakran inkább dinamikus, mint statikus, jellegük van. Például egy chat alkalmazásban vagy egy beszélgetés során a modell korábbi kommunikációja nagyban befolyásolja, hogy milyen legyen a következő válasz. A kérdés az, hogy hogyan értékeljük számszerűen egy adott válasz minőségét, hogy azt jutalomként kezelhessük.
Jutalom
Csak akkor tudunk valamit pontozni, ha van valami, amivel össze lehet hasonlítani. Tehát először is többféle választ kell kapnunk ugyanarra a kérdésre. Ehhez két módon juthatunk el. Egyrészt használhatunk egyetlen előre tanított modellt, ami válaszai egy kicsit véletlenszerűek. Az alapmodellnek különböző valószínűségeket kell rendelnie a különböző válaszokhoz, és nem mindig a legvalószínűbbet kell választani. A másik lehetőség az, hogy különböző, előre tanított modelleket használunk, akár teljesen más architektúrával. Ezek biztosan másféle válaszokat adnak majd.
Rendben, eljutottunk oda, hogy több különböző válaszunk van ugyanarra a kérdésre. A következő lépés, hogy meghatározzuk ezeknek a válaszoknak a minőségét. Itt érkezünk meg az Emberi Visszajelzéshez. Ekkor egy szakértő vagy egy csoport emberi felügyelő értékeléseket ad a rendszernek. Gyakorlatilag az emberek rangsorolják a korábban előállított válaszokat. A rangsorolás a kulcsfontosságú. Elméletben lehetne abszolút skálán pontozni a válaszokat, de sok probléma van ezzel a módszerrel. A legnagyobb gond az, hogy nagyon inkonzisztens. Különböző egyének még akkor is eltérő pontot adnak ugyanarra a válaszra, ha a válaszok sorrendje megegyezik. Ennek az lehet az oka, hogy mindenki más optimális válaszhoz hasonlítja a valós kimeneteket. Emiatt a gyakorlatban inkább a válaszok sorrendjét használjuk jutalomként. Ennek is egy speciális változatát, amit “páros rangsorolásnak” (angolul: pairwise comparison vagy relative ranking) nevezünk. Ez azt jelenti, hogy a rangsorolást végző személy nem az összes lehetséges választ látja, hanem csak két véletlenszerűen kiválasztott mintát. Ezzel a módszerrel jelentősen nő a rangsorolás egyöntetűsége. Természetesen, ha több lehetséges válaszunk van, akkor ezekből a páros rangsorolásokból ki kell alakítanunk egy abszolút sorrendet. Ez nem túl bonyolult:
Nézzünk egy példa pontozást. Jelöljük a válaszokat 0 értékkel, ha rosszabbak a párosított párjuknál, 1 értékkel, ha jobbak, és 0,5 értékkel, ha ugyanolyan jók mint a párjuk. Tegyük fel, hogy 4 lehetséges válaszunk van (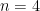
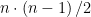
| 1. válasz | 2. válasz | 3. válasz | 4. válasz | Összeg | |
| 1. válasz | – | 1 | 0 | 0,5 | 1,5 |
| 2. válasz | 0 | – | 0 | 1 | 1 |
| 3. válasz | 1 | 1 | – | 0 | 2 |
| 4. válasz | 0,5 | 0 | 1 | – | 1,5 |
A fenti példában az első válasz jobb a másodiknál, de rosszabb a harmadiknál. Az abszolút sorrend kialakításához össze kell adnunk az egyes sorok értékeit, mint ahogy azt az “Összeg” oszlop jelzi. Vagyis a példában a harmadik válasz lesz a legjobb, az első és a negyedik a következő helyezést érik el, míg a második válasz a legkevésbé kedvező.
Miután ez megvan, tanítanunk kell egy modellt a pontozott válaszokkal. Ez azért szükséges, mert nem lehetséges minden lehetséges beszélgetést előre elkészíteni és osztályozni. Szükségünk van egy modellre, amely képes a konkrét emberi visszajelzéseket általánosabb szintre emelni. Fontos megemlíteni, hogy egy teljesen új modellt kell tanítanunk, nem az alapmodell vagy annak egyes rétegeit hangoljuk finomra ebben a lépésben. Ez a modell az alapmodell után fog működni, és Megerősített Tanulásos Nyelvi Modellnek (MT) nevezzük.
Ezt a modellt az emberi visszajelzéseken fogjuk tanítani, és természetesen akkor jutalmazzuk, ha az a válaszainál az emberi preferenciákhoz hasonlóak. Ezt a jutalmat 
A fenti rendszert így ábrázolnánk:

Finomra hangolás
Most, hogy a Megerősített Tanulásos (MT) modellünk készen áll, finomhangolhatjuk az eredeti Nagy Nyelvi Modellünket (NNyM). Ehhez általában célszerű egy részét a súlyoknak befagyasztani, tekintettel arra, hogy az MT kevesebb adaton lett tanítva, mint az eredeti modellünk.
A finomhangolás alapötlete egyszerű: készítsünk különböző kimeneteket a Nagy Nyelvi Modellhez, pontozzuk őket az MT segítségével, és a jutalomnak megfelelően frissítsük a nem fagyasztott súlyokat a Nagy Nyelvi Modellben. A ChatGPT 3.5 és 4. esetén erre a Proximális Stratégia Optimalizáció (angolul: Proximal Policy Optimization) algoritmust használták. Ezt így lehetne ábrázolni:

A Proximális Stratégia Optimalizációt 2017-ben publikálta az OpenAI. Először is nézzük meg, milyen probléma megoldására született. A Grádienscsökkentésről szóló bejegyzésben már volt szó a lépésközről, ismételjük át nagy vonalakban. Tömören a lépésköz azt mutatja meg nekünk, hogy mekkora távolság legyen a jelenlegi és a következő beállítások között. Ha nagy lépésközzel dolgozunk, akkor gyorsan fogunk haladni, de ez azt is jelenti, hogy ha rossz irányba indulunk el, akkor gyorsabban fogunk az optimális értéktől távolodni. Ha kis lépésekkel haladunk, lassan, de biztosan fogunk haladni, a kérdés az, hogy van-e elég időnk kivárni a célba érkezést. Nem nehéz belátni, hogy a Grádienscsökkentés lépésköze a Megerősített Tanulás során is szerepet játszik. Ilyenkor a lépésköz azt jelzi, hogy milyen gyakran kap valaki jutalmat vagy büntetést. Ha sokat várunk, mielőtt kiszámítanánk a jutalom mértékét, vagyis nagy lépésközzel dolgozunk, gyorsan fog haladni az ügynökünk, de lehetséges, hogy túl későn realizálja, hogy rossz irányba fut. Ha gyakran osztunk jutalmakat, vagyis kicsi a lépésköz, akkor viszont lassú lesz az ügynök előrehaladása
Ideális esetben az algoritmus magától határozná meg a lépésközt, és a körülményekhez megfelelően állítaná azt. Ha nem állna fent a rossz irányba fordulás veszélye, gyorsan haladna, ha viszont bizonytalan, akkor kisebb lépésekkel. A Grádienscsökkentés esetén, a derivált értéke ezt a feladatot látja el (természetesen megfelelően nagy tanulási rátával ez is elrontható). Sajnos, a Megerősített Tanulás során nem optimális a Grádienscsökkentés alkalmazása. Ez az algoritmus azon a feltételezésen alapul, hogy van egy statikus optimum, amit lényegében csak meg kell találni, és ez az optimum független az algoritmustól. A Megerősített Tanulás esetén viszont az optimum nem független, hanem az ügynök (algoritmus) korábbi lépéseitől és annak stratégiájától is függ. Ráadásul, mivel a tanulási folyamat során remélhetőleg az ügynök fejlődik, egyre újabb és újabb helyzetekkel találja magát szemben. Vegyük például a sakkozást (a Megerősített Tanulást gyakran használják játékokban.). Az optimum eléréséhez, a játék megnyeréséhez nem egyetlen út vezet, és még ha lenne is egyetlen optimális út, az sem lenne statikus. Az ellenfél játékstratégiája és a saját tudásszintünk is folyamatosan alakítja, hogy milyen módon érhető el a cél.
Ennek a nagyon zajos veszteségfüggvénynek a kezelésére dolgozták ki a Stratégia Gradiens Módszert (angolul: Policy Gradient Method). Készítettem egy ábrát a jobban megértésük mit is csinál ez:

Ilyenkor az ügynök egy adott állapotban gyűjti az összes lehetséges akció jutalmát egy T jövőbeli intervallumra. Mielőtt továbbmennénk, gondolkozzunk el azon, hogy mi az akció egy GPT modell esetén. Nagy vonalakban a GPT nem tesz mást, mint megpróbálja kitalálni a következő szót egy adott szövegkörnyezetben. Ennek megfelelően a kimenete egy valószínűségi érték minden egyes, a szótárában szereplő kifejezéshez. A konkrét valószínűségek azt fejezik ki, hogy milyen eséllyel válasszuk ki az adott szót a következőnek. Mi az akció ilyenkor? Természetesen az egyes szavak kiválasztása. Vegyük észre, hogy nem feltétlenül a legnagyobb valószínűségű szót kell kiválasztanunk minden egyes esetben. Mit szeretnénk a finomhangolással elérni? Azt, hogy az egyes szavak kiválasztásának valószínűségét úgy módosítsuk, hogy minél nagyobb jutalmat kapjunk utána. Az egyes akciók (szavak kiválasztása) után kapott jutalmat így számszerűsíthetjük:
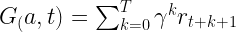
Ahol:
— az akció kezdetének állapota
— k lépéssel az akció kezdetét jelentő t állapot után
— végső állapot
— súly
— jutalom egy adott állapotban
— egy akció teljes jutalma, (angolul Discounted reward)
Ez elég egyszerű: egy konkrét állapotból kiindulva kipróbálunk egy lehetséges akciót és megnézzük, mennyi jutalmat tudunk az akciónk után begyűjteni. Ezeket a jutalmakat
Érdemes megjegyezni, hogy az akció utáni jutalmak a neurális hálónk konkrét állapotától függenek. Ez annak következménye, hogy minden esetben az adott állapotnak megfelelő legjobb lépést fogjuk kiválasztani az akció utáni T lépésben. Ennek viszont van egy következménye: egy zajos értéket fogunk kapni az akció jóságáról.
Ahhoz, hogy számszerűsítsük, hogy egy korábban számított akció (
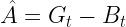
Ahol:
— Előny (angolul Advantage function) kifejezi, hogy egy akció relatíve mennyire jó.
— az alap jutalom
Mi ez a
A fenti normalizáció után elméletileg már képesek lennénk a kimeneti réteg súlyainak finomhangolására, de még nem esett szó arról, hogy hogyan oldjuk meg, hogy az egyes frissítések se túl kicsik, se túl nagyok ne legyenek. Ezt oldja meg a Proximális Stratégiai Optimalizáció. Ez a módszer nagy vonalakban határok köze szorítja a Stratégia Grádiens Módszerben számolt jutalmat. Vagyis ha a jutalom hatására nagyon meg akarnánk változtatni egy adott szó kiválasztásának valószínűségét, a Proximális Stratégia Optimalizáció ezt meg fogja akadályozni, és csak egy konzervatív frissítés fog megtörténni. Ez a viselkedés megakadályozza, hogy olyan frissítést hajtsunk végre, amit később nem tudunk visszavonni. A PSO konkrét számítása túlmutat ezen a bejegyzésen, így itt csak maradjunk annyiban, hogy a limit határai között a
Kullback–Leibler távolság
Természetesen a fenti finomra hangolás után a modell kimenete megváltozik az eredeti alapmodelléhez képest. Remélhetőleg jobb szöveget fog generálni, de felmerülhet egy probléma. Megtörténhet, hogy a Finomra Hangolt modell a Megerősített Tanulásos modell hatására egy teljesen más szöveget generál, csak azért, hogy az emberi visszajelzéseknél tanultaknak minél jobban megfeleljen. Ennek elkerülése érdekében a ChatGPT 3.5-ben kiegészítették egy újabb elemmel a jutalmazás számítását. Konkrétabban: elkezdték mérni, hogy a Finomra Hangolt modell által készített szöveg mennyire hasonlít az Alapmodell által generálthoz. Erre a két szöveg Kullback-Leibler távolságát használják. Minél inkább hasonlít a Finomhangolt modell válasza az Alapmodellére, annál nagyobb jutalmat kap. Vagyis a ChatGPT 3.5 esetén a Proximális Stratégia Optimalizációban használt jutalom két részből áll össze:

Ahol:
— végső jutalom
— az emeberi visszajelzésen alapuló jutalom
— az Kullback-Leibler távolsága az Alapmodell és az MT kimenetének
— ez a hiperparaméter gyakorlatilag egy súly, amellyel beállítható, hogy mennyire preferáljuk a Finom Hangolt modell által generált szöveg hasonlóságát az Alapmodelléhez.
Ha a KL számítást is hozáadjuk a fenti NNyM tanulási ábrához, akkor így lehetne ábrázolni a teljes Megerősitett Tanulás Emberi Visszajelzésből:

Összegzés
Ha kellő távolságból nézzük ezt az architektúrát, lényegében két modellt látunk: Egy sok, de rossz minőségű adaton tanított nagy modellt, és egy kisebb, de jó minőségű adaton tanított modellt. Ez a felállás tulajdonképpen egy gyakran felmerülő kérdést reprezentál a gépi tanulásban: Mi a jobb, sok rossz minőségű adat, vagy kevés jó minőségű? Természetesen kevés adattal csak kisebb modellt lehet tanítani, de ez a kisebb modell az adatok minősége miatt még így is versenyképes lehet egy bonyolultabb, de rossz adaton tanított modellhez képest.
Szerintem a ChatGPT azért lett igazán áttörő, mert sikerült ötvöznie ezt a két alapvetően más filozófiát. A fenti architektúra lehetővé teszi, hogy egy nagy, de gyenge adatokon tanított nyelvi modellt, mint a ChatGPT 3, egy kisebb, de jó minőségű modell segítségével finomra hangoljunk. Ennek persze ára van. Ez a módszer csakis jó minőségű, emberek által ellenőrzött adatokkal működik, ami drága. Gyakran teljes állásban kell hozzá alkalmazni munkavállalókat.
Az, hogy mekkora a Megerősített Tanulásos Nyelvi Modell, változik a különböző cégeknél. Az OpenAI a 175 milliárd paraméterű GPT-3 alapmodell mellé egy 6 milliárd paraméteres Megerősített Tanulásos modellt készített. Ezzel szemben a DeepMind 70 milliárd paraméterű Chinchilla modelljéhez szintén egy 70 milliárd paraméteres Megerősített Tanulásos modellt használ.
Irodalom
- Nathan Lambert, Louis Castricato, Leandro von Werra & Alex Havrilla: Illustrating Reinforcement Learning from Human Feedback (RLHF)
- Robert & Cai: ChatGPT Statistics 2023
- Bala Manikandan: Demystifying ChatGPT: A Deep Dive into Reinforcement Learning with Human Feedback
- Ayush Thakur: Understanding Reinforcement Learning from Human Feedback (RLHF): Part 1
- Marco Ramponi: How ChatGPT actually works
- Pairwise comparison method
- Detoxifying a Language Model using PPO
- Arxiv Insights: Mastering Reinforcement Learning with Policy Gradient Methods
