A sorozat célja, hogy a Statisztika alap fogalmait tisztázza minél közérthetőben.
A Loss függvényt tipikusan optimalizációs problémák megoldására szokták alkalmazni. A kérdés amire válaszol: melyik az a modell ami leginkább illeszkedik a mintavételi pontjainkra.
Mint mindent, ezt is egy példa alapján lehet a legjobban megérteni, ezért nézzünk is egyet. Az alábbi példában van egy 20 pontból álló mintánk.1
És két modellünk, A és B. Ahol 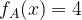


Ha valaki megnézi a fenti ábrát, akkor mindenféle matematikai ismeret nélkül is a B modellt fogja jobbnak gondolni. Miért? Puszta intuíció alapján: míg az A lényegében a mintákon kívül van, addig a B a pontok között. Logikusan a B-nek kell jobbnak lennie.
De mi van ha a modellek nem sokkal közelebb helyezkednek el egymáshoz. Például van egy modell C, ami: 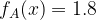

Ez már nehezebb. Puszta intuíció itt valószínűleg már nem elég. Mi lenne akkor, ha megmérnénk a távolságot az egyes mérések és a modellek között külön-külön. Valahogy így:


Ha most összeadjuk minden egyes modell esetén ezeket a távolságokat, akkor lényegében kapunk egy számot ami megmondja, hogy a pontok összesített távolsága mekkora az adott modelltől. Értelemszerűen minél nagyobb ez a szám, annál rosszabb a modell, mivel annál távolabb van a pontoktól. Lényegében ez a loss függvény. Egy olyan mérőszám, ami leírja a modell menyire illeszkedik az adatokra. És azért loss mert lényegében ez egy negatív mérőszám, ha nagyobb akkor a modell rosszabb.3 A fenti konkrét példák esetén ez az összesített távolság az A esetén: 68.09, a B-nél 28.09, míg az C modellnél 27.29. Vagyis a legjobb modell ez esetben a C.
Vegyük észre, hogy semmi nem gátol meg minket abban, hogy teljesen eltérő modelleket hasonlítsunk össze. Tehát pl: modell D lehetne 
Persze az élet nem olyan egyszerű. Az alap koncepció a fenti példa alapján egyértelmű, de azért rengetek konkrét megvalósítása van. Néhány a teljesség igénye nélkül:
- mean squared error – Itt lényegében a fenti távolság négyzetét használjuk a mérésre. Ennek a problémája, hogy érzékeny a kiugró adatokra. Értelemszerűen ha négyzetre emeljük a távolságot, egy hibás adat sokkal jobban képes elvinni a számítást.
- abszolút loss – Ez lényegében a fenti példa. A probléma ezzel a függvénnyel, hogy nem deriválható.
- Huber loss – Ez hasonlít az abszolút loss-ra, de egy kritikus tartományban (0-hoz közel) egy folytonos, és így deriválható értéket használ. Ennek köszönhetően a Huber loss robusztus mint egy abszolút loss, és deriválható mint egy mean squared loss.
A fentiek alapján könnyű elképzelni, hogy egy lineáris legkisebb négyzetek regresszió során mi zajlik a háttérben. Lényegében kipróbálunk egy rakás lineáris modellt, és a végén az kerül kiválasztásra, aminél a loss függvény eredménye a legkisebb. Persze van itt egy kis probléma: végtelen számú lehetséges modell létezik. Szóval egyrészt nem próbálhatunk ki minden modellt, másrészt meg kell oldani, hogy minél több olyan modellt próbáljunk ki aminek értelme is van. Ennek tárgyalása viszont túlmutat ezen a bejegyzésen.
Szintén érdemes beszélni még a objektív függvény fogalmáról. Az objektív függvény lényegében egy olyan függvény amit minimalizálni vagy maximalizálni szeretnénk. Ebből a definícióból nem nehéz kitalálni, hogy a loss függvény az objektív függvények egyik alcsoportja. Viszont vannak olyan függvények is, amiket nem minimalizálni, hanem maximalizálni akarunk. Ezeket több néven forognak forgalomban. Területtől függően lehet jutalom, haszon vagy például fitnesz. A statisztikában a likelihood függvény talán a leggyakrabban használt függvény amit maximalizálni szeretnénk. Vegyük észre, hogy a maximalizálás és a minimalizálás ugyanaz a probléma. Ha egy függvényt, amit maximalizálni akarunk megszorzunk -1-el, akkor egyből minimalizációs probléma lesz belőle. Ilyen értelemben bármelyik objektív függvényt loss függvényé lehet alakítani.
Lábjegyzet
- A konkrét példában ezek a minták:
[2.05253717, 3.66050933, 2.22244529, 0.05081167, 1.24078878, 2.26312505
2.55583001, 0.3978853, 3.17131423, 0.26266108, 3.95012571, 1.67145317,
1.3092976, 2.22637725, 1.30363927, 0.71808774, 1.16943084, 0.23491089,
0.94394966, 1.62288187, 0.24653088, 3.12785466, 1.22392622, 3.67275408,
1.48586155, 2.42088967, 2.34121977, 0.71808342, 1.31260781, 2.33601541] - Vegyük észre, hogy távolságról van szó, nem pedig különbségről. A távolság mindig pozitív.
- A közgazdaságtanban szokták még “cost” (“költség”) függvénynek is nevezni. Ami utal arra a képzelettársításra, hogy költséget minél alacsonyabban szeretnénk tartani. Hogy bonyolódjon a dolog néha a cost függvényt a loss kiterjesztéseként használják. Pl: loss+valami büntetés ha a modell bonyolultabb.

“A Loss függvény – statisztika alapok” bejegyzéshez 8 hozzászólás